
Taras Khakhulin
Member of Technical Staff, Research
Runway
I’m a Member of Technical Staff (Research) at Runway where I build the next generation of controllable, aesthetic video models. I authored Act-2 – the first publicly available omni-model that enables full-body precise control for motion capture. Before joining Runway I spent 2+ years at Synthesia working on novel-view synthesis, human reconstruction and video diffusion, including HumanRF (SIGGRAPH ’23) with high-fidelity neural radiance fields for humans in motion. During my Ph.D. studies at Skoltech I worked as a researcher at Samsung Lab, bringing neural-rendering technology for view synthesis and one-shot animation to real-world mobile and XR devices. During my studies I contributed to 3D representations, image synthesis and human avatars. Prior to that, in my master’s I investigated reinforcement-learning approaches for discrete optimisation, and even earlier I was part of the DeepPavlov project where we developed robust word representations for noisy texts using context-aware language models.
Research

ACM ToG, SIGGRAPH 2023
HumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion
Mustafa Işık, Martin Rünz, Markos Georgopoulos, Taras Khakhulin, Jonathan Starck, Lourdes Agapito, Matthias Nießner
Introduced high-resolution dataset of human performances to speed up development in avatars. Also, we demonstrated ability to reconstruct large scenes with temporal factorization for 4D NeRFs.

WACV 2023
Self-improving Multiplane-to-layer Images for Novel View Synthesis
Pavel Solovev*, Taras Khakhulin*, Denis Korzhenkov*
Create the most efficient renderable representation for novel view synthesis from an arbitrary number of images (more than one). We learn this system end-to-end on the dataset of monocular videos. Extremely fast and compact way to present scene.

ECCV 2022
Realistic One-shot Mesh-based Head Avatars
Taras Khakhulin, Vanessa Sklyarova, Victor Lempitsky, Egor Zakharov
Create an animatable avatar just from a single image with coarse hair mesh and neural rendering. We learn head geometry and rendering together with supreme quality in a cross-person reenactment.


CVPR 2022
Stereo Magnification with Multi-Layer Images
Taras Khakhulin, Denis Korzhenkov, Pavel Solovev, Gleb Sterkin, Andrei-Timotei Ardelean, Victor Lempitsky
The scene can be represented as a set of semi-transparent mesh layers from just stereo pair without loss of the quality. This representation allows effortless estimation and fast rendering. Additionally, we published a dataset with occluded region - SWORD - for novel view synthesis.

CVPR 2021
🎤 Oral Presentation
Image Generators with Conditionally-Independent Pixel Synthesis
Ivan Anokhin, Kiril Demochkin, Taras Khakhulin, Gleb Sterkin, Victor Lempitsky, Denis Korzhenkov
Our generator produce images without any spatial convolutions. Each pixel synthesized separately conditioned on noise vector. We investigate properties of such generator and propose several applications (e.g. super-res, foveated rendering).
Learning Meets Combinatorial Algorithms, NeurIPS Workshop 2020
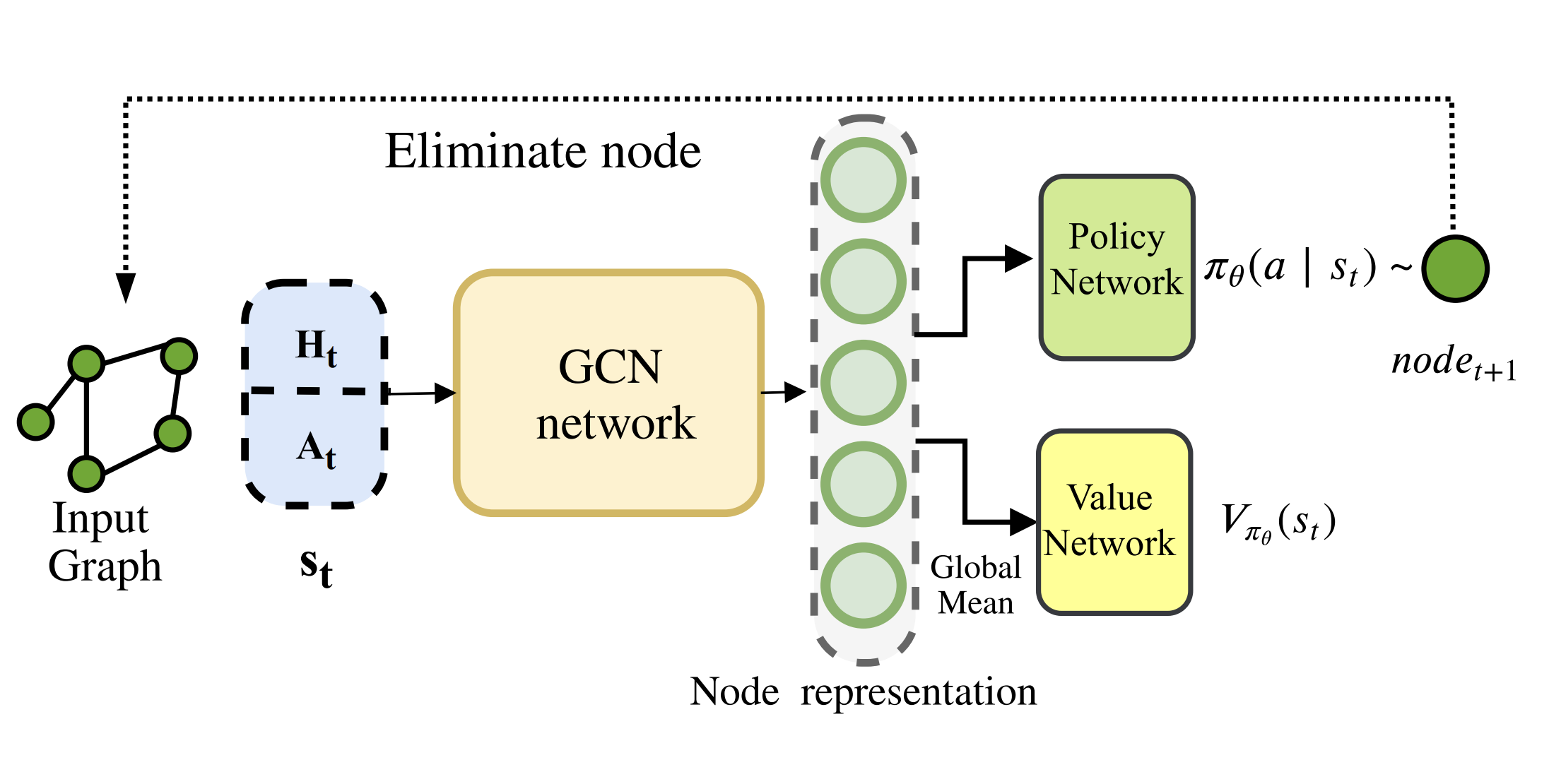
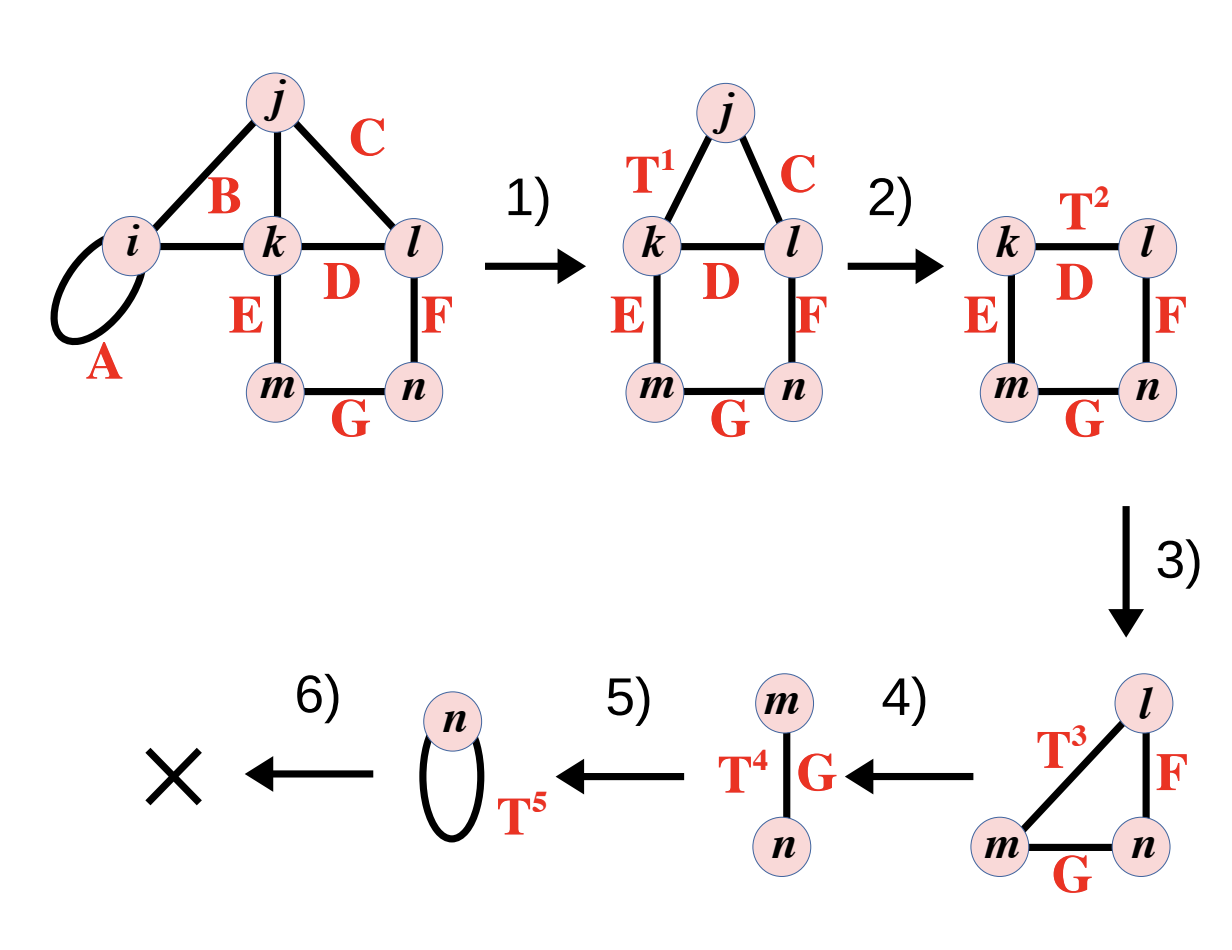
Learning Elimination Ordering for Tree Decomposition Problem
Taras Khakhulin, Roman Schutski, Ivan Oseledets
We propose a learning heuristic with RL for real-world combinatorial problem on graphs. Surprisingly, we can easily estimate universal policy which can be scaled across different graphs.

CVPR 2020
🎤 Oral Presentation
High-Resolution Daytime Translation Without Domain Labels
Ivan Anokhin*, Pavel Solovev*, Denis Korzhenkov*, Alexey Kharlamov*, Taras Khakhulin, Alexey Silvestrov, Sergey Nikolenko, Victor Lempitsky, Gleb Sterkin
High-resolution image-to-image translation without domain labels, enabling daytime style transfer at unprecedented quality.
Physical Review A 2020
Simple heuristics for efficient parallel tensor contraction and quantum circuit simulation
Roman Schutski, Dmitry Kolmakov, Taras Khakhulin, Ivan Oseledets
The heuristic approach based on tree decomposition to relax the contraction of tensor networks using probabilistic graphical models and applied for random quantum circuits.
Workshop on Noisy User-generated Text at EMNLP 2018
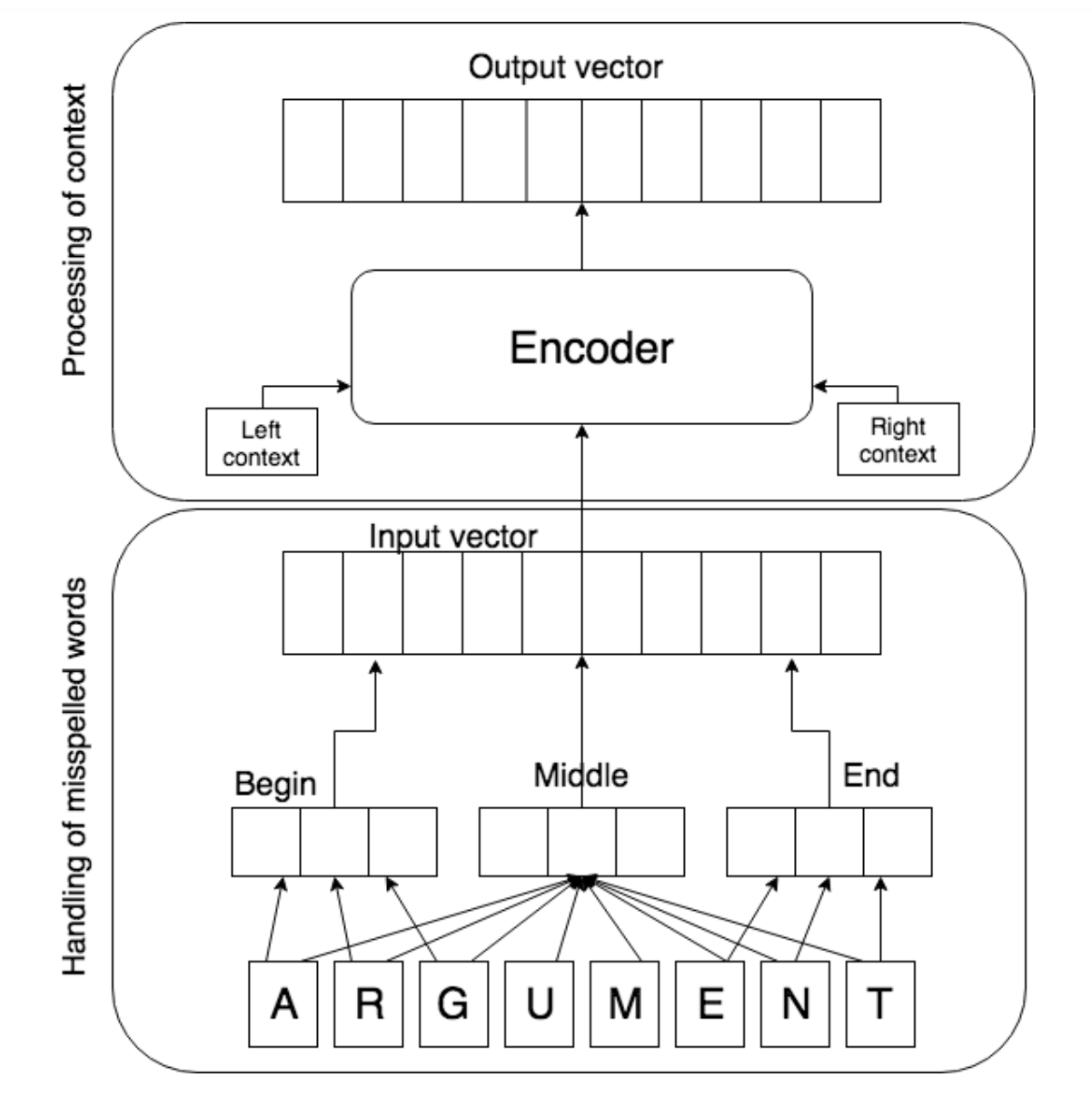
Robust word vectors: context-informed embeddings for noisy texts
Valentin Malykh, Varvara Logacheva, Taras Khakhulin
We suggest a new language-independent architecture of robust word vectors (RoVe). It is designed to alleviate the issue of typos, which are common in almost any user-generated content, and hinder automatic text processing.

ACL, System Demonstrations 2018
Deeppavlov: Open-source library for dialogue systems
Mikhail Burtsev, Alexander Seliverstov, Rafael Airapetyan, Mikhail Arkhipov, Dilyara Baymurzina, Nickolay Bushkov, Olga Gureenkova, Taras Khakhulin, Yuri Kuratov, Denis Kuznetsov, Alexey Litinsky, Varvara Logacheva, Alexey Lymar, Valentin Malykh, Maxim Petrov, Vadim Polulyakh, Leonid Pugachev, Alexey Sorokin, Maria Vikhreva, Marat Zaynutdinov
Open-source library for end2end conversational NLP.
Experience
Research Engineer — Synthesia • London/Edinburgh, UK
Led projects on novel-view synthesis, video diffusion and human avatars. Key work: HumanRF (SIGGRAPH ’23), non-rigid reconstruction pipelines and human avatar diffusion-based systems.
Research Engineer — Samsung Lab • Moscow, Russia
Worked on neural rendering and stereo magnification; developed one-shot head avatars for 3D priors and high-resolution portraits (e.g. StereoLayers, RoMe).